This page reflects the status as of 2008-01-17. The documentation is still incomplete. Target audience is developers and users who would like to get an in-depth understanding of queues as used in rsyslog.
Please note that this document is outdated and does not longer reflect the specifics of the queue object. However, I have decided to leave it in the doc set, as the overall picture provided still is quite OK. I intend to update this document somewhat later when I have reached the "store-and-forward" milestone.
A queue is DA-enabled if it is configured to use disk-assisted mode when there is need to. A queue is in DA mode (or DA run mode), when it actually runs disk assisted.
Memory-Type queues may utilize disk-assisted (DA) mode. DA mode is enabled whenever a queue file name prefix is provided. This is called DA-enabled mode. If DA-enabled, the queue operates as a regular memory queue until a high water mark is reached. If that happens, the queue activates disk assistance (called "runs disk assisted" or "runs DA" - you can find that often in source file comments). To do so, it creates a helper queue instance (the DA queue). At that point, there are two queues running - the primary queue's consumer changes to a shuffle-to-DA-queue consumer and the original primary consumer is assigned to the DA queue. Existing and new messages are spooled to the disk queue, where the DA worker takes them from and passes them for execution to the actual consumer. In essence, the primary queue has now become a memory buffer for the DA queue. The primary queue will be drained until a low water mark is reached. At that point, processing is held. New messages enqueued to the primary queue will not be processed but kept in memory. Processing resumes when either the high water mark is reached again or the DA queue indicates it is empty. If the DA queue is empty, it is shut down and processing of the primary queue continues as a regular in-memory queue (aka "DA mode is shut down"). The whole thing iterates once the high water mark is hit again.
There is one special case: if the primary queue is shut down and could not finish processing all messages within the configured timeout periods, the DA queue is instantiated to take up the remaining messages. These will be preserved and be processed during the next run. During that period, the DA queue runs in "enqueue-only" mode and does not execute any consumer. Draining the primary queue is typically very fast. If that behaviour is not desired, it can be turned of via parameters. In that case, any remaining in-memory messages are lost.
Due to the fact that when running DA two queues work closely together and worker threads (including the DA worker) may shut down at any time (due to timeout), processing synchronization and startup and shutdown is somewhat complex. I'll outline the exact conditions and steps down here. I also do this so that I know clearly what to develop to, so please be patient if the information is a bit too in-depth ;)
Three cases:
In case 1, the worker pool is running. When switching to DA mode, all regular workers are sent termination commands. The DA worker is initiated. Regular workers may run in parallel to the DA worker until they terminate. Regular workers shall terminate as soon as their current consumer has completed. They shall not execute the DA consumer.
In case 2, the worker pool is not yet running and is NOT started. The DA worker is initiated.
In case 3, the worker pool is already shut down. The DA worker is initiated. The DA queue runs in enqueue-only mode.
In all cases, the DA worker starts up and checks if DA mode is already fully initialized. If not, it initializes it, what most importantly means construction of the queue.
Then, regular worker processing is carried out. That is, the queue worker will wait on empty queue and terminate after an timeout. However, If any message is received, the DA consumer is executed. That consumer checks the low water mark. If the low water mark is reached, it stops processing until either the high water mark is reached again or the DA queue indicates it is empty (there is a pthread_cond_t for this synchronization).
In theory, a case-2 startup could lead to the worker becoming inactive and terminating while waiting on the primary queue to fill. In practice, this is highly unlikely (but only for the main message queue) because rsyslog issues a startup message. HOWEVER, we can not rely on that, it would introduce a race. If the primary rsyslog thread (the one that issues the message) is scheduled very late and there is a low inactivty timeout for queue workers, the queue worker may terminate before the startup message is issued. And if the on-disk queue holds only a few messages, it may become empty before the DA worker is re-initiated again. So it is possible that the DA run mode termination criteria occurs while no DA worker is running on the primary queue.
In cases 1 and 3, the DA worker can never become inactive without hitting the DA shutdown criteria. In case 1, it either shuffles messages from the primary to the DA queue or it waits because it has the hit low water mark.
In case 3, it always shuffles messages between the queues (because, that's the sole purpose of that run). In order for this to happen, the high water mark has been set to the value of 1 when DA run mode has been initialized. This ensures that the regular logic can be applied to drain the primary queue. To prevent a hold due to reaching the low water mark, that mark must be changed to 0 before the DA worker starts.
In essence, DA run mode is terminated when the DA queue is empty and the primary worker queue size is below the high water mark. It is also terminated when the primary queue is shut down. The decision to switch back to regular (non-DA) run mode is typically made by the DA worker. If it switches, the DA queue is destructed and the regular worker pool is restarted. In some cases, the queue shutdown process may initiate the "switch" (in this case more or less a clean shutdown of the DA queue).
One might think that it would be more natural for the DA queue to detect being idle and shut down itself. However, there are some issues associated with that. Most importantly, all queue worker threads need to be shut down during queue destruction. Only after that has happend, final destruction steps can happen (else we would have a myriad of races). However, it is the DA queues worker thread that detects it is empty (empty queue detection always happens at the consumer side and must so). That would lead to the DA queue worker thread to initiate DA queue destruction which in turn would lead to that very same thread being canceled (because workers must shut down before the queue can be destructed). Obviously, this does not work out (and I didn't even mention the other issues - so let's forget about it). As such, the thread that enqueues messages must destruct the queue - and that is the primary queue's DA worker thread.
There are some subleties due to thread synchronization and the fact that the DA consumer may not be running (in a case-2 startup). So it is not trivial to reliably change the queue back from DA run mode to regular run mode. The priority is a clean switch. We accept the fact that there may be situations where we cleanly shut down DA run mode, just to re-enable it with the very next message being enqueued. While unlikely, this will happen from time to time and is considered perfectly legal. We can't predict the future and it would introduce too great complexity to try to do something against that (that would most probably even lead to worse performance under regular conditions).
The primary queue's DA worker thread may wait at two different places:
Case 2 is unlikely, but may happen (see info above on a case 2 startup).
The DA worker may also not wait at all, because it is actively executing and shuffeling messages between the queues. In that case, however, the program flow passes both of the two wait conditions but simply does not wait.
Finally, the DA worker may be inactive (again, with a case-2 startup). In that case no work(er) at all is executed. Most importantly, without the DA worker being active, nobody will ever detect the need to change back to regular mode. If we have this situation, the very next message enqueued will cause the switch, because then the DA run mode shutdown criteria is met. However, it may take close to eternal for this message to arrive. During that time, disk and memory resources for the DA queue remain allocated. This also leaves processing in a sub-optimal state and it may take longer than necessary to switch back to regular queue mode when a message burst happens. In extreme cases, this could even lead to shutdown of DA run mode, which takes so long that the high water mark is passed and DA run mode is immediately re-initialized - while with an immediate switch, the message burst may have been able to be processed by the in-memory queue without DA support.
So in short, it is desirable switch to regular run mode as soon as possible. To do this, we need an active DA worker. The easy solution is to initiate DA worker startup from the DA queue's worker once it detects empty condition. To do so, the DA queue's worker must call into a "DA worker startup initiation" routine inside the main queue. As a reminder, the DA worker will most probably not receive the "DA queue empty" signal in that case, because it will be long sent (in most cases) before the DA worker even waits for it. So it is vital that DA run mode termination checks be done in the DA worker before it goes into any wait condition.
Please note that the "DA worker startup initiation" routine may be called concurrently from multiple initiators. To prevent a race, it must be guarded by the queue mutex and return without any action (and no error code!) if the DA worker is already initiated.
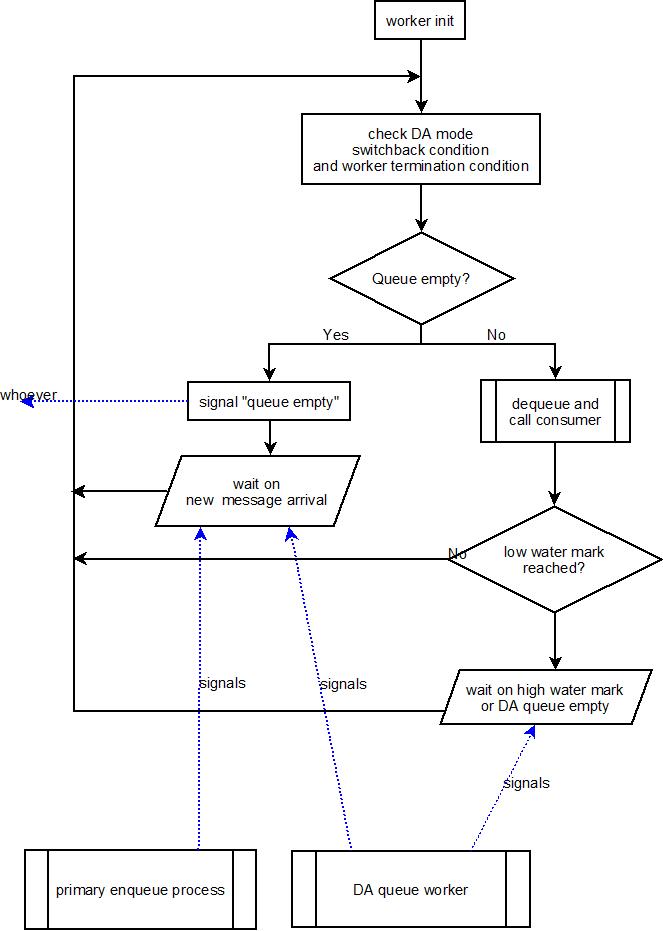
All other cases can be handled by checking the termination criteria immediately at the start of the worker and then once again for each run. The logic follows this simplified flow diagram:
Some of the more subtle aspects of worker processing (e.g. enqueue thread signaling and other fine things) have been left out in order to get the big picture. What is called "check DA mode switchback..." right after "worker init" is actually a check for the worker's termination criteria. Typically, the worker termination criteria is a shutdown request. However, for a DA worker, termination is also requested if the queue size is below the high water mark AND the DA queue is empty. There is also a third termination criteria and it is not even on the chart: that is the inactivity timeout, which exists in all modes. Note that while the inactivity timeout shuts down a thread, it logically does not terminate the worker pool (or DA worker): workers are restarted on an as-needed basis. However, inactivity timeouts are very important because they require us to restart workers in some situations where we may expect a running one. So always keep them on your mind.
Now let's consider the case of destruction of the primary queue. During destruction, our focus is on loosing as few messages as possible. If the queue is not DA-enabled, there is nothing but the configured timeouts to handle that situation. However, with a DA-enabled queue there are more options.
If the queue is DA-enabled, it may be configured to persist messages to disk before it is terminated. In that case, loss of messages never occurs (at the price of a potentially lengthy shutdown). Even if that setting is not applied, the queue should drain as many messages as possible to the disk. For that reason, it makes no sense to wait on a low water mark. Also, if the queue is already in DA run mode, it does not make any sense to switch back to regular run mode during termination and then try to process some messages via the regular consumer. It is much more appropriate the try completely drain the queue during the remaining timeout period. For the same reason, it is preferred that no new consumers be activated (via the DA queue's worker), as they only cost valuable CPU cycles and, more importantly, would potentially be long(er)-running and possibly be needed to be cancelled. To prevent all of that, queue parameters are changed for DA-enabled queues: the high water mark is to 1 and the low water mark to 0 on the primary queue. The DA queue is commanded to run in enqueue-only mode. If the primary queue is configured to persist messages to disk before it is terminated, its SHUTDOWN timeout is changed to to eternal. These parameters will cause the queue to drain as much as possible to disk (and they may cause a case 3 DA run mode initiation). Please note that once the primary queue has been drained, the DA queue's worker will automatically switch back to regular (non-DA) run mode. It must be ensured that no worker cancellation occurs during that switchback. Please note that the queue may not switch back to regular run mode if it is not configured to persist messages to disk before it is terminated. In order to apply the new parameters, worker threads must be awakened. Remember we may not be in DA run mode at this stage. In that case, the regular workers must be awakened, which then will switch to DA run mode. No worker may be active, in that case one must be initiated. If in DA run mode and the DA worker is inactive, the "DA worker startup initiation" must be called to activate it. That routine ensures only one DA worker is started even with multiple concurrent callers - this may be the case here. The DA queue's worker may have requested DA worker startup in order to terminate on empty queue (which will probably not be honored as we have changed the low water mark).
After all this is done, the queue destructor requests termination of the queue's worker threads. It will use the normal timeouts and potentially cancel too-long running worker threads. The shutdown process must ensure that all workers reach running state before they are commanded to terminate. Otherwise it may run into a race condition that could lead to a false shutdown with workers running asynchronously. As a few workers may have just been started to initialize (to apply new parameter settings), the probability for this race condition is extremely high, especially on single-CPU systems.
After all workers have been shut down (or cancelled), the queue may still be in DA run mode. If so, this must be terminated, which now can simply be done by destructing the DA queue object. This is not a real switchback to regular run mode, but that doesn't matter because the queue object will soon be gone away.
Finally, the queue is mostly shut down and ready to be actually destructed. As a last try, the queuePersists() entry point is called. It is used to persists a non-DA-enabled queue in whatever way is possible for that queue. There may be no implementation for the specific queue type. Please note that this is not just a theoretical construct. This is an extremely important code path when the DA queue itself is destructed. Remember that it is a queue object in its own right. The DA queue is obviously not DA-enabled, so it calls into queuePersists() during its destruction - this is what enables us to persist the disk queue!
After that point, left over queue resources (mutexes, dynamic memory, ...) are freed and the queue object is actually destructed.
Copyright (c) 2008 Rainer Gerhards and Adiscon.
Permission is granted to copy, distribute and/or modify this document under the terms of the GNU Free Documentation License, Version 1.2 or any later version published by the Free Software Foundation; with no Invariant Sections, no Front-Cover Texts, and no Back-Cover Texts. A copy of the license can be viewed at http://www.gnu.org/copyleft/fdl.html.